
机器学习的数据隐私(1/3)-差分隐私
隐私保护机器学习是一个非常活跃的研究领域。这里将解释最有技术背后的一些原理并展示一些实用的案例,来说明如何将它们适配进机器学习流水线。
这次将通过几篇文章,分别介绍3种用于隐私保护机器学习的主要方法:差分隐私、联邦学习和加密的机器学习。
数据隐私问题
数据隐私是关于信任和限制曝光人们原本希望保密的数据内容。隐私保护机器学习有很多不同的方法,为了在它们之间进行选择,你应该尝试回答以下问题:
- 你试图向谁保密?
- 系统的哪些部分可以是私有的,哪些可以公开?
- 谁是可以查看数据的可信方?
这些问题的答案将帮助你确定哪种方法最适合你的用例。
为什么关心数据隐私
数据隐私正在成为机器学习项目的重要组成部分。围绕用户隐私有许多法律要求,比如,于2018年5月生效的欧盟的《通用数据保护条例》(GDPR)和于2020年1月生效的《加利福尼亚州消费者隐私法案》。把个人信息用作机器学习的数据是有道德问题的,那些用着由机器学习提供能力的产品的用户们开始深切关注他们的数据后期会发生什么。由于机器学习一贯依赖数据,并且机器学习模型做出的许多预测是基于从用户那里收集的个人数据,因此机器学习处于数据隐私纷争的最前沿。
目前,涉及隐私是要付出代价的:加入隐私会带来模型准确率、计算时间或两者均涉及的代价。在一种极端情况下,不收集任何数据会使交互完全保密,但对机器学习一点儿用处也没有。在另一种极端情况下,知道一个人的所有细节可能会损害这个人的隐私,但是这使我们能够建立非常准确的机器学习模型。我们已经开始设想隐私保护机器学习的开发,其可以在不对模型准确率进行较大妥协的情况下加入隐私。
在某些场景中,隐私保护机器学习可以帮助你使用由于隐私问题而无法用于训练机器学习模型的数据。然而,它并不是仅因为你使用了一种方法即可让你自由地掌控数据。你应该与其他干系人(比如数据所有者、隐私权专家,甚至你公司的法律团队)讨论你的计划。
最简单的增加隐私的方法
通常,构建由机器学习提供支持的产品的默认策略是收集所有可能的数据,然后再决定哪些对训练机器学习模型有用。尽管这是在用户同意的情况下完成的,但增加用户隐私的最简单方法是仅收集训练特定模型所需的数据。对于结构化数据,可以简单地删除姓名、性别或种族等字段。文本或图像数据可以被处理以删除许多个人信息,比如从图像中删除面孔或从文本中删除姓名。但是,在某些情况下,这可能会降低数据的实用性或使其无法训练准确的模型。而且,如果没有收集有关种族和性别的数据,就无法判断模型是否对特定群体有偏见。
对收集哪些数据的控制权也可以交给用户:与简单地选择加入或退出相比,收集数据的授权可能会更加细致,产品的用户可以确切指定能够收集关于他们的哪些数据。这就带来了设计挑战:提供较少数据的用户是否比提供更多数据的用户获得了更少的准确预测?如何通过机器学习流水线跟踪授权?如何衡量隐私对模型中单个特征的影响?这些都是机器学习社区中需要进行更多讨论的问题。
哪些数据需要保密
在机器学习流水线中,数据通常是从人们那里收集的,但是某些数据对隐私保护机器学习有更高的要求。个人识别信息(personally identifyinginformation,PII)是可以直接识别一个人的数据,比如他们的姓名、电子邮件地址、街道地址、ID号等,因此需要保密。PII会出现在自由文本里,比如反馈评论或客户服务数据,而不仅仅是在直接要求用户提供此数据时。在某些情况下,人像也可以被视为PII。围绕这方面通常有法律标准,如果你的公司有隐私权团队,最好在着手使用此类数据的项目之前咨询他们。
敏感数据也需要特别注意,通常将它定义为如果发布可能会对某人造成伤害的数据,比如健康数据或专有的公司数据(比如财务数据)。应注意确保在机器学习模型的预测中不会泄露此类数据。
另一类是“准标识”数据。如果已知足够多的准标识符,比如位置跟踪或信用卡交易数据,则准标识符可以唯一地标识某人。如果已知有关同一个人的多个位置点,则这将提供一种可以与其他数据集组合的唯一追踪来重新识别这个人。2019年12月,《纽约时报》发表了一篇深入介绍使用手机数据进行重新标识的文章(Twelve Million Phones, One Dataset, Zero Privacy),这还只代表了几种质疑此类数据发布的意见里的一种。
差分隐私
如果在机器学习流水线中发现需要额外的隐私,那么可以使用多种方法来帮助增加隐私性,同时保留尽可能多的数据实用性。我们将讨论的第一个问题是差分隐私(differential privacy,DP)。“差分隐私”源自Cynthia Dwork的文章“Differential Privacy”,这篇文章被收录在《密码学与安全百科全书》一书中。差分隐私是这样一种想法的形式化:一个查询或数据集的转换不应该揭示某个人是否在该数据集中。它定义了一个人被加入数据集中所遭受的隐私损失这样一个数学度量,并通过添加噪声将隐私损失降至最低。
换句话说,如果将一个人从该数据集中删除,则尊重隐私的数据集的变换不应发生变化。在机器学习模型的场景下,如果在考虑隐私的情况下对模型进行了训练,那么如果从训练集中删除一个人,则模型所做的预测不应更改。DP通过在转换中添加某种形式的噪声或随机性来实现。
举一个更具体的例子,实现差分隐私的一个最简单的方法就是随机回复的概念,如图1所示。 这在提出敏感问题的调查中很有用,比如“你曾被判为犯罪吗?”为了回答这个问题,被问到的人会抛硬币。如果出现正面,他们就如实回答。如果出现背面,则再抛一次硬币。如果硬币是正面,回答“是”;如果硬币是背面,回答“否”。这给了他们推脱之辞:他们可以说给出的是随机答案,而不是真实的答案。由于我们知道抛硬币的概率,因此如果问很多人这个问题,就可以以合理的准确率来计算被判为犯罪的人数比例。当更多的人参加调查时,计算的准确率将提高。
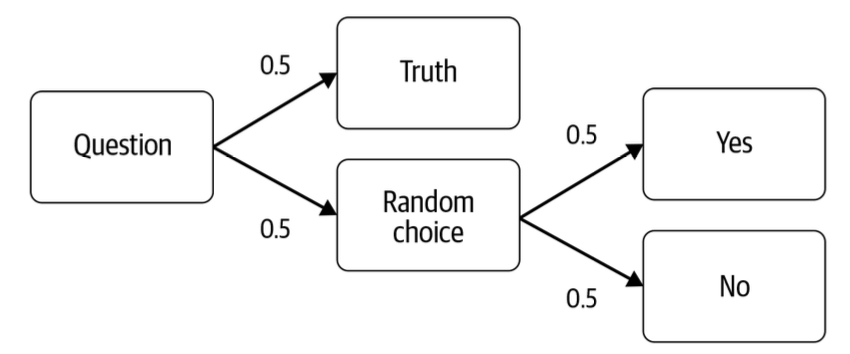
图1 随机回复流程图
这些随机转换是DP的关键。
假设每人一个训练样本
为简单起见,本文会假设数据集中的每个训练样本都与一个人相关或是从一个人那里收集到的。
局部差分隐私和全局差分隐私
DP可以分为两种主要方法:局部DP和全局DP。在局部DP中,如先前的随机回复案例所示,在个人级别添加了噪声或随机性,因此在个人与数据采集者之间保持了隐私。在全局DP中,噪声会被添加到整个数据集的转换中。数据采集者与原始数据是可以信任的,但是转换结果不会显示有关个人的数据。
与局部DP相比,全局DP只要求添加更少的噪声,这可以提高查询的实用性或准确率,从而获得相似的隐私保证。不利之处在于,数据采集者必须被全局DP信任,而对于局部DP,只有一个个用户看得到他们自己的原始数据。
Epsilon、Delta和隐私预算
实现DP的最常见方法可能是用ε–δ(epsilon–delta)DPε。当比较包含某一特定人的数据集上的随机转换结果与不包含该人的另一结果时,eε描述了这些转换结果之间的最大差异。因此,如果ε为0,说明两个转换会返回完全相同的结果。如果ε的值较小,则转换将返回相同结果的可能性更大——ε的值越小越隐私,因为ε会衡量隐私保证的强度。如果多次查询数据集,则需要对每个查询的ε求和,以获取总的隐私预算。
δ是ε不成立的概率,或个体数据在随机变换结果中被暴露的概率。通常将δ设置为人数规模的倒数:对于包含2000人的数据集,将δ设置为1/1000。有关其背后的数学运算的更多细节,请参见Dwork和Roth合著的The Algorithmic Foundations of Differential Privacy。
应该选择什么值作为ε呢?ε使我们能够比较不同算法和方法的隐私,但是赋予我们“足够”隐私的绝对值取决于使用场景。
为了确定要用于ε的值,当ε减小时,对系统的准确率可能会有所帮助。选择最私密的参数,同时保留对业务问题可接受的数据实用性。或者,如果泄露数据的后果非常严重,则你可能希望先设置可接受的ε和δ值,然后调整其他超参数以获得可能的最佳模型准确率。 ε–δ DP的一个弱点是ε不容易解释。我们正在开发其他方法来帮助解决此问题,比如在模型的训练数据中植入秘密,并衡量在模型预测中暴露这些秘密的可能性。
机器学习的差分隐私
如果希望将DP用作机器学习流水线的一部分,有一些当前可行的选项能加入DP,尽管我们希望将来会看到更多。第一种选项,DP可以包含在联邦学习系统中,并且可以使用全局DP或局部DP。第二种选项,TensorFlow Privacy库是全局DP的一个例子:原始数据可用于模型训练。
第三种选项是“教师模型全体的隐私聚合”(private aggregation of teacher ensemble,PATE)方法。这是一种数据共享方案:假设有10个人有标记好的数据,但你没有,他们会在局部训练模型并各自对你的数据做出预测。然后执行DP查询来针对数据集中的每个样本生成最终预测,这样你便不知道10个模型中哪个做了预测。然后,根据这些预测训练出一个新模型,该模型通过一种无法了解这些隐藏数据集的方法囊括了来自10个隐藏数据集的信息。PATE框架展示了在这种场景下如何使用ε。
本文节选自我参与翻译的《机器学习流水线实战》,并做了重新编辑。 阅读更多内容,可以购买实体书:https://item.jd.com/10039673039939.html
comments powered by Disqus