
机器学习的数据隐私(2/3)-联邦学习
联邦学习(federated learning,FL)是一种协议,其中机器学习模型的训练分布在许多不同的设备上,并且训练后的模型在中心服务器上进行合并。关键点是原始数据永远不会离开单独的设备,也永远不会被集中在一个地方。这与在一个集中的地方收集数据集然后训练模型的传统架构大不相同。
FL通常在拥有分布式数据的手机或用户浏览器环境中很有用。另一个潜在的使用场景是共享分布在多个数据所有者之间的敏感数据。例如,一个AI初创公司想训练模型以检测皮肤癌。皮肤癌的图片归许多医院所有,但由于隐私和法律方面的考虑,无法将它们集中在一个地方。FL能够使初创企业在数据不离开医院的情况下训练模型。
在FL设置中,每个客户端都会收到模型架构和一些训练指令。我们会在每个客户端的设备上训练模型,并将权重返回到中央服务器。这会稍微增加隐私性,因为相对于原始数据,一个拦截器更难从模型权重中了解有关用户的任何信息,但它不能提供任何隐私性的保证。分布式模型训练这一步并不能在公司收集数据过程中为用户提升更多隐私性,因为公司通常可以在了解模型架构和权重的情况下得出原始数据原本是什么样的。
不过,使用FL提高隐私性还有一个很重要的步骤:将权重安全地聚合到中央模型中。有很多算法可以做到这一点,但是它们都要求中央模型必须是可信的,不会试图在合并权重之前对其进行查看。
图1展示了在FL设置中哪些参与方可以访问用户的个人数据。公司可能会收集数据来设置安全聚合,这样它们就不会看到用户返回的模型权重了。中立的第三方也可以执行安全聚合。在这种情况下,只有用户才能看到他们的数据。
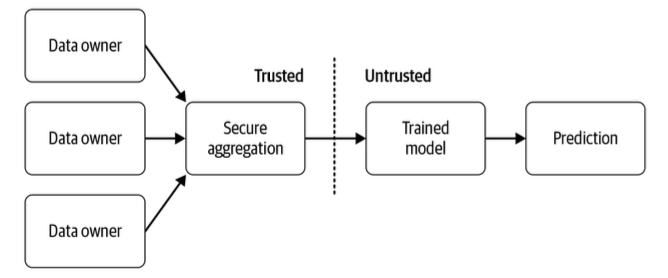
图1 联邦学习中的受信方
FL的另一个隐私保护扩展是将DP合并到此技术中。在这种情况下,DP会限制每个用户可以为最终模型提供信息的数量。研究表明,如果用户数量很大,那么生成的模型几乎与无DP模型一样准确。不过,到目前为止,其尚未在TensorFlow或PyTorch中实现。
一个生产环境中的FL案例是Android手机的Google Gboard键盘。谷歌可以训练模型以做出更好的下一词预测,而无须了解用户的隐私消息。FL在具有以下特征的场景中最有用:
- 模型所需的数据只能从分布式的来源收集;
- 数据源的数量很大;
- 数据在某种程度上是敏感的;
- 数据不需要额外的打标(标签可以由用户直接提供,不会离开源);
- 理想情况下,数据是从几乎相同的分布中提取的。
FL在机器学习系统的设计中引入了许多新的考虑因素,例如,并非所有数据源都在一次训练和下一次训练之间收集了新数据,并非所有移动设备都始终处于开启状态,以此类推……所收集的数据通常是不平衡的,并且实际上对于每个设备都是唯一的。当设备池很大时,最容易为每次训练获得足够的数据。必须为任何使用了FL的项目开发新的安全基础设施。
必须注意避免在训练FL模型的设备上出现性能问题。训练会迅速耗尽移动设备上的电量或导致大量的流量被使用,从而给用户带来费用。尽管移动电话的处理能力正在迅速增强,但它们仍然只能训练小型模型,因此应在中央服务器上训练更复杂的模型。
TensorFlow中的联邦学习
TensorFlow Federated(TFF)会模拟FL的分布式设置,并包含一个可以计算分布式数据更新的随机梯度下降(stochastic gradient descent,SGD)版本。常规SGD要求梯度更新是对中心化数据集的batch计算出来的,然而在联邦设置中不存在这样的中心化数据集。目前,TFF主要针对新的联邦算法进行研究和实验。
PySyft是由OpenMined组织开发的开源Python平台,用于隐私保护机器学习。它包含使用安全的多方计算来聚合数据的FL实现。它最初是为支持PyTorch模型而开发的,但已经发布了TensorFlow版本。
本文节选自我参与翻译的《机器学习流水线实战》,并做了重新编辑。 阅读更多内容,可以购买实体书:https://item.jd.com/10039673039939.html
comments powered by Disqus